Overview
Abstract
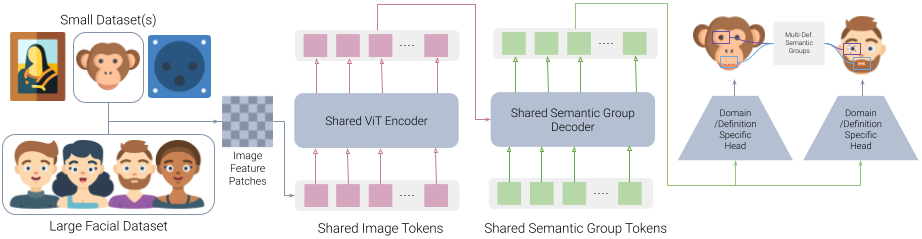
We present a novel method for multi image domain and multi-landmark definition learning for small dataset facial localization. Training a small dataset alongside a large(r) dataset helps with robust learning for the former, and provides a universal mechanism for facial landmark localization for new and/or smaller standard datasets. To this end, we propose a Vision Transformer encoder with a novel decoder with a definition agnostic shared landmark semantic group structured prior, that is learnt, as we train on more than one dataset concurrently. Due to our novel definition agnostic group prior the datasets may vary in landmark definitions and domains. During the decoder stage we use cross- and self-attention, whose output is later fed into domain/definition specific heads that minimize a Laplacian-log-likelihood loss. We achieve state-of-the-art performance on standard landmark localization datasets such as COFW and WFLW, when trained with a bigger dataset. We also show state-of-the-art performance on several varied image domain small datasets for animals, caricatures, and facial portrait paintings. Further, we contribute a small dataset (150 images) of pareidolias to show efficacy of our method. Finally, we provide several analysis and ablation studies to justify our claims.
Poster